我们应该怎样判断风险的等级
(by axis, 转载请注明出处)
漏洞是安全的主要话题,但不是全部。在很多时候会出现一种困扰,就是某个漏洞到底是否重要,往往是公说公有理,婆说婆有理。
程序员一般会和安全人员在这个问题上扯皮,比如一个XSS,程序员很可能就认为这个问题不重要,或者优先级不是特别高,而安全人员往往会绞尽脑汁的去提高漏洞的重要程度,可能会伴随有一系列的POC演示去吓唬程序员。但是在很多时候,往往漏洞是没有POC的,这时候该怎么办?
更多的时候,安全人员需要去说服或者教育老板什么是安全的,以帮助其做决策。而老板都是很精明的主,如果拿不出很充分的数据或者证据来说明漏洞或者威胁为什么重要,他往往会降低安全方案的优先级别(商业公司环境下)。
所以风险评估过程中,非常重要的一步就是如何给风险评级,量化风险。
实际上,目前已知的所有描述方法都是希望用定量的方法去描述一个定性的问题,所以我认为,这些方法都只能参考,并没有一个权威的标准。
比较简单,有这样的公式:
Risk = Probability * Damage
把风险描述为可能性与造成损失的积。 这个描述还是有一定的依据的。
其实并非每个漏洞都需要补,比如某个溢出漏洞,在当前环境下利用极其困难或者说基本上没法利用,那么这个漏洞就可以说是风险等级较低,因为 Probability的分数会很低。
再具体点,比如MS08-001,是windows上的tcpip.sys 里的一个漏洞,涉及到TCP/IP协议栈,连端口都不需要就可以攻击,看起来威力强大,但是这个漏洞由于随机性太强,也导致基本无法利用,顶多DOS一下。
所以我们需要一种更加科学的方法来描述风险。
在我公司的SDL里,我通常喜欢用 DREAD 模型(取首字母)来描述风险:
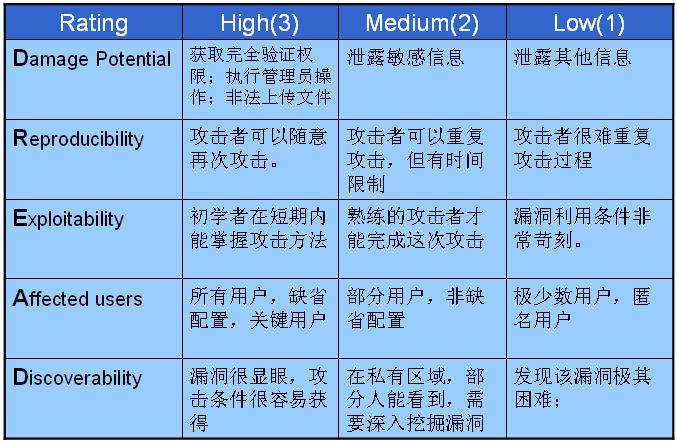
这个模型的5项分别是: 潜在危害、重复利用的可能性、利用的困难程度、受影响用户范围、发现的难易程度。
这个模型从5个方面来描述,视角比较全面,对于每一项都有3个等级,对应着权重,从而形成了一个矩阵。
在量化风险的过程中,可以对每个威胁进行评分:
Risk = D + R + E + A + D
最后得出来,如果是 5-7 分,则是低风险; 8-11分,则是中等风险;12-15分,则是高风险。
如果说要扩展这个模型,我觉得可以多加一项权重,0分,然后计算方法把求和变成求积,这要更能拉开分数差距,而且还把0分的极端情况考虑进来了。
0分的极端情况是什么情况? 就是一个漏洞变成一个bug的情况。比如这个漏洞是很牛B,被人利用了就会导致直接root机器,但是就是没人能够接触到这个input的位置,所以没人 能够利用这个漏洞,这样affected users这项就会是0分,最后一求积,整体风险 0 分, 漏洞不需要修补,因为没人能利用。
当然这个例子有点极端,0分的情况一定要慎用,在上例中,以后代码可能会出现些变动,导致原来无法控制input的地方变得可以控制了,就会导致一个0分的风险,马上变成最高的风险。这又从一个侧面证明:安全是一个持续的过程!
其他类似的评估风险的方法还有很多,比如再加一个修正因子之类。
风险评估结束后,就可以依据风险的等级,判断优先级,从而给决策和架构设计提供有力的科学依据,就不再是纯粹凭借经验来做事,不再山寨了!

好羡慕你的工作呢,呵呵。
我可以考虑一下转行~